FASHNAI



















FASHN VTON v1.5: Efficient Maskless Virtual Try-On in Pixel Space
Built for consumer-facing virtual try-on with interactive performance. Given a person image and garment image, generates photorealistic results directly in pixel space without requiring segmentation masks.
Abstract
Virtual try-on methods based on latent diffusion face two fundamental challenges: 1) warping garment details in latent space introduces distortion, making it difficult to preserve colors, logos, patterns, and textures, and 2) without true try-on triplets for training (images of the same person wearing different garments in identical poses), the field has adopted masking approaches that erase body-specific characteristics and constrain transformation volume. FASHN VTON v1.5 addresses both challenges with three key properties: 1) pixel-space generation that operates directly on RGB pixels without VAE encoding, preserving garment details, 2) maskless inference that generates try-on results without masking, preserving body identity and removing volume constraints, and 3) interactive performance with a 972M parameter architecture optimized for ~5 second inference on H100 GPUs. FASHN VTON v1.5 demonstrates that pixel-space generation combined with maskless inference enables high-fidelity virtual try-on suitable for consumer-facing applications. Released under Apache 2.0, FASHN VTON v1.5 is the first permissive open-source virtual try-on model and one of few pixel-space diffusion architectures publicly available for research and commercial use.
Method
Architecture
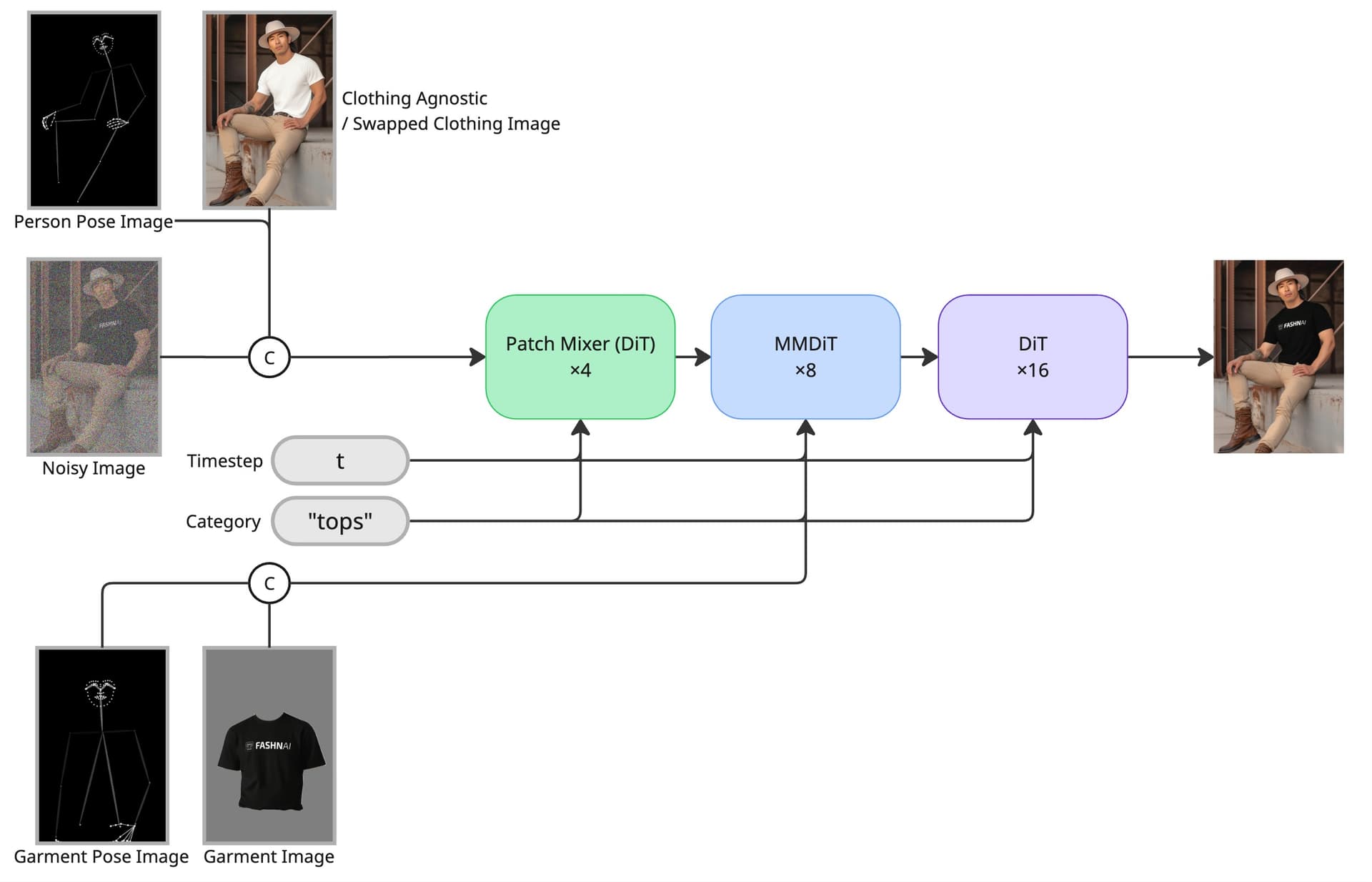
FASHN VTON v1.5 uses an MMDiT [1] architecture that processes person and garment images jointly. 8 double-stream blocks handle cross-modal attention between person and garment tokens, followed by 16 single-stream blocks for self-attention over the concatenated sequence. 4 patch-mixer blocks [2] pre-process image patches before the main transformer.
The model operates directly on RGB pixels instead of compressed latent space. The only spatial reduction is a 12×12 patch embedding. Pose keypoints are provided as single-channel grayscale images concatenated to the person and garment inputs. Category embeddings ("tops", "bottoms", "one-pieces") are added to timestep conditioning.
Training
FASHN VTON v1.5 was trained from scratch in two phases. Phase 1 trained on 18M masked try-on pairs. Phase 2 trained on a 50/50 mix of masked pairs and 4M synthetic triplets generated by the Phase 1 checkpoint. These triplets consist of people wearing alternative garments paired with their originals as ground truth, enabling the model to perform try-on from an unmasked input while preserving body shape.
Training from scratch in pixel space is computationally demanding. The patch-mixer blocks addressed this by allowing up to 75% of tokens to be dropped during training, significantly reducing memory and compute requirements.
Results
The key advantage of maskless inference is freedom from the constraints imposed by segmentation masks. The examples below compare v1.5 against FASHN VTON v1, the previous state-of-the-art which relied on masked inference. They highlight challenging scenarios: voluminous garments that exceed the original outfit's boundaries, hair regions where the original garment leaks through due to segmentation errors, tattoos and body characteristics that masked methods typically erase, and cultural garments like hijabs that require preservation during swaps.

Pants to skirt: When swapping pants to a skirt, masked inference constrains the output to the original pants boundaries. Segmentation-free mode freely adjusts volume to fit the skirt naturally while preserving body shape.

Tattoo preservation: Masked inference erases skin details in the garment region. Segmentation-free mode fully preserves the model's tattoos and keeps the original pants intact since only the top is being swapped.

Voluminous wedding gown: Masked inference limits the gown to the original outfit's boundaries, cutting off volume. Segmentation-free mode expands freely to fit the full wedding gown silhouette.

Turtleneck sweater dress: Masked inference struggles with the loose turtleneck collar and oversized sleeves. Segmentation-free mode transfers these garment details with higher fidelity.

Longline t-shirt: The longline t-shirt extends below typical top length. Masked inference clips to the original top boundaries, while segmentation-free mode extends the garment naturally.

Kurta top: This traditional kurta extends below the knee. Masked inference constrains the garment to standard top length, while segmentation-free mode handles the full volume expansion.

Puffer jacket on tight clothing: The model wears a slim-fitting outfit, but the target is a bulky puffer jacket. Masked inference restricts volume to the original silhouette, while segmentation-free mode expands realistically.

Floor-length mermaid gown: This mermaid gown flows to the floor and covers the feet. Masked inference cuts off at the original garment boundaries, while segmentation-free mode renders the full length.

Hair occlusion (dark garment): When hair overlaps the garment area, masked inference misclassifies parts of the original dark garment as hair, causing it to leak through. Segmentation-free mode avoids this by not relying on segmentation.

Hair occlusion (light garment): Similar to dark garments, the original light-colored garment leaks through hair strands due to segmentation errors in masked inference. Segmentation-free mode preserves clean hair appearance.

Hijab preservation: Masked inference often misclassifies the hijab as part of the garment region, causing distortion. Segmentation-free mode correctly preserves the head covering during the swap.

Layered outfit: The model wears a jacket over a top. Masked inference often includes the outer layer, causing unwanted changes. Segmentation-free mode selectively replaces only the inner top while keeping the jacket intact.
Limitations
- Resolution: Output is limited to 576×864 compared to 1K+ resolutions achievable with VAE-based architectures.
- Body preservation: Maskless inference significantly improves body preservation compared to masked methods, but is not yet perfect. Since synthetic triplets were generated by a masked model, some body characteristics may still shift slightly.
- Garment removal: In maskless mode, the original garment may not be fully removed, especially in long-to-short transitions or bulky-to-slim conversions. The model preserves body shape but may leave traces of the original clothing.

Garment traces at hem: The model wears a gray t-shirt and the target is a "Top Gun" t-shirt. Masked inference follows the original garment too closely, making the fit too long. Segmentation-free mode fits the garment correctly but leaves traces of the original gray fabric at the hem.

Bulky-to-slim conversion: The model wears a voluminous purple tulle dress and the target is a slim green blazer dress. Masked inference produces a distorted result with altered footwear. Segmentation-free mode fits the blazer correctly and preserves the original shoes, but leaves the original purple tulle visible below the new garment.
References
- Esser et al. "Scaling Rectified Flow Transformers for High-Resolution Image Synthesis" (ICML 2024)
- Sehwag et al. "Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget" (2024)
Citation
If you use FASHN VTON v1.5 in your research, please cite our work:
@article{bochman2026fashnvton,
title={FASHN VTON v1.5: Efficient Maskless Virtual Try-On in Pixel Space},
author={Bochman, Dan and Bochman, Aya},
journal={arXiv preprint},
year={2026},
note={Paper coming soon}
}FASHN VTON v1.5 is released under the Apache 2.0 License.