Comparing the Top 4 Open Source Virtual Try On (VITON) Models
I compare the top open-source virtual try on (VITON) models against each other to figure out once and for all, which performs best.

Have you noticed that every virtual try on model makes claims of “photo realistic try on” and “accurate fitting”, when in reality quality varies wildly? I’m going to pit the top VITON models against each other to figure out once and for all, which performs best.
Today we’re going to be making the top 4 open source virtual try on models (and one mystery model) compete head-to-head in a showdown.
What is a Virtual Try on Model?
A virtual try on model lets you digitally put clothes on any person with AI.
How Does It Work?
A virtual try-on model works by first identifying and masking out existing clothing in a photo and then generating a new outfit in that region. Modern implementations lean on latent diffusion, which take your person image plus a mask and a garment image as conditioning inputs, then “inpaint” the masked area to produce a seamless try-on result.
Which Virtual Try On (VITON) Models Are We Testing?
Let me introduce you to the 4 models that we’ll be putting head-to-head to compete with each other today…
StableVITON
StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On (GitHub Banner)
StableVITON is a historical precursor to the models in this comparison and was posted on arXiv, December 4 2023. It appeared at the Conference on Computer Vision and Pattern Recognition (CVPR) in 2024. The repo shows 1.2k stars and 190+ forks on GitHub.
Technical Approach:
Inspired by ControlNet, StableVITON introduces a learnable copy of Stable Diffusion’s encoder and injects its output into the decoder’s cross-attention layers. Similar to ControlNet, only the duplicated encoder and the connecting layers are trained (🔥), while the rest of the original Stable Diffusion (SD) model remains frozen (❄️). The model fine-tunes from pre-trained SD 1.5 weights and aims to guide image generation using visual inputs instead of textual prompts.
Model Inputs:
- The main UNet (original SD) ❄️ receives:
- A clothing-agnostic image of the person (with clothing masked or erased)
- A binary mask
- A DensePose map
- The Garment Encoder (ControlNet-style branch) 🔥 receives:
- The garment image as its primary input
- CLIP embeddings ❄️ of the garment image injected into its encoder layers. This acts as a replacement to text tokens to leverage SD's original weights.
StableVITON for Dummies:
Stable Diffusion is already a powerful text-to-image generator. StableVITON adds a smart helper to it: a small network that learns how to guide the model using clothing images instead of text. It figures out where the clothes should go on the person and how to blend them naturally. Think of it like giving Stable Diffusion a visual reference and saying, “Make the person wear this, and make it look real.”
Editor's note: StableVITON is the oldest model in this list, and as such, its results won't be included as they were not up to par with the rest of the models that I tested. There are no working live demos available online to test this model easily.
OOTDiffusion
OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (GitHub Banner)
OOTDiffusion’s paper was published on arXiv, March 4 2024 and now sits in the Association for the Advancement of Artificial Intelligence (AAAI) proceedings. The project boasts 6.3k stars and 900+ forks on GitHub plus a very popular Hugging Face Space (1k stars).
Technical Approach:
Inspired by Google's TryOnDiffusion: A Tale of Two UNets, OOTDiffusion adopts the idea of using two parallel UNets, but with Stable Diffusion 1.5 as a base.
While Google didn’t release official code, you can find our unofficial implementation here.
OOTDiffusion runs two separate UNets in parallel:
- The Outfitting UNet 🔥 specializes in understanding the garment. It processes the clothing image layer-by-layer and shares what it learns at each stage with the other UNet.
- The Main UNet (Denoising UNet) 🔥 is responsible for generating the final image of the person wearing the outfit. It takes cues from the Outfitting UNet through specialized cross-attention layers known as "outfitting-fusion layers".
Unlike StableVITON's approach that only influences the model during decoding, OOTDiffusion starts feeding clothing information much earlier in the generation pipeline. This helps the model integrate fine details throughout the try-on process.
OOTDiffusion also fine-tunes from SD1.5 checkpoints rather than training from scratch.
Model Inputs:
- Outfitting UNet receives:
- The garment image
- CLIP image embedding
- Optional CLIP text embeddings (e.g., garment labels like upper-body, lower-body)
- Main UNet receives:
- A clothing-agnostic image of the person (with clothing masked out)
📌 Note: In contrast to other models, OOTDiffusion does not use any explicit pose information.
OOTDiffusion for Dummies:
Imagine instead of giving advice to one expert (like in StableVITON), you train two experts who work side-by-side. They talk to each other at every step; One expert studies the clothing image in detail (the shape, patterns, textures) while the other focuses on fitting those clothes onto the person so it would look natural.
Comparison Notes:
- Despite being quite popular in the past, its HF Space is currently broken. A look into the comments section showed that it has been throwing errors for the last 2 months.
- For the purpose of this comparison, we've used this Replicate endpoint.
- The Replicate demo took 110 seconds to get 4 try on results.
- Lower body garments are not supported in OOTDiffusion.
IDM-VTON

IDM-VTON: Improving Diffusion Models for Authentic Virtual Try-on in the Wild (GitHub Banner)
IDM-VTON was published on arXiv on March 8 2024 and was chosen for the European Conference on Computer Vision in 2024. By June 2025 it had drawn 4.6k stars and 730+ forks on GitHub and has a widely used Hugging Face demo.
Technical Approach:
IDM-VTON builds on the two-parallel-UNets approach but introduces a novel twist using Stable Diffusion XL (SDXL) as its foundation.
- The Garment UNet (GarmentNet) ❄️ is frozen and serves purely as a feature extractor, capturing fine clothing details like textures, buttons, and patterns.
- The Main UNet (TryOnNet) 🔥 is trainable and is responsible for generating the final try-on image.
- A third module, the IP-Adapter 🔥, acts as a trainable helper. It learns from the garment image and provides strong guidance early in the generation process.
Feature Fusion
- Garment UNet features are integrated into TryOnNet via self-attention (concatenation)
- IP-Adapter features are injected via cross-attention (standard IP-Adapter method)
This structure allows IDM-VTON to generate detailed and realistic try-on images while leveraging existing SDXL weights.
Model Inputs
TryOnNet
- Clothing-agnostic image of the person (same as in StableVITON)
GarmentNet
- Garment image
- Garment text description (e.g., "short sleeve round neck t-shirt")
IP-Adapter
- Garment image
IDM-VTON for Dummies:
Previous methods mostly tried to guide pre-trained models like Stable Diffusion by adding external modules that “influenced” the generation process from the side. IDM-VTON takes a bolder approach: instead of just guiding, it focuses on training the main model (UNet) directly, while using frozen helper modules to extract garment details and shape cues. This makes the core model itself smarter at the try-on task.
Quick facts: Auto mask on linked demo took 50 seconds, virtual try on took 20 seconds, so a minute and 10 seconds for a try on. The auto mask only worked on tops, and I had to manually mask the pants area with a brush to get it working with pants, which was not convenient.
CatVTON
CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models (GitHub Banner)
CatVTON (“Concatenation Is All You Need”) was published on arXiv, July 21 2024 and has already been accepted to the International Conference on Learning Representations in 2025. As of June 2025 the open-source repo has about 1.4k stars and 160+ forks on GitHub.
Technical Approach:
CatVTON breaks away from the two-parallel-UNet trend used by models like StableVITON, OOTDiffusion, and IDM-VTON. Instead of running separate networks for garments and people, CatVTON uses a single, compact UNet and a clever spatial trick to handle both inputs at once.
Rather than injecting garment information through cross-attention or extra channels, CatVTON simply concatenates the garment and person images side by side across the spatial dimension. This combined input is passed through a single network, which learns to process them together as one image.
The result is a lightweight model (899M total parameters, with only 49M trainable) capable of generating high-resolution 1024×768 try-on images, and it can run on consumer GPUs with less than 8GB of VRAM.
CatVTON is not trained from scratch either; it’s a fine-tune. Multiple versions exist, each starting from a different base (e.g., SDXL, FLUX, DiT), but the core idea stays the same: a simplified, efficient architecture that trades complexity for speed and accessibility.
Model Inputs (Single Network)
- Clothing-Agnostic Image + Garment Image: Concatenated side by side across the spatial dimension (e.g., [Person | Garment])
- Clothing-Agnostic Mask:
- Concatenated as an additional channel
- Aligned spatially with the person image portion only
📌 Note: CatVTON also does not incorporate any pose information.
CatVTON for Dummies:
Explained simply, instead of using complex connection systems like other models, CatVTON literally tapes the clothes picture next to your photo (side by side in the image space) and lets one compact network do everything. This simple approach makes it quick on an everyday gaming PC yet still produces sharp, realistic results.
Quick facts: For this test, we use the latest version of CatVTON paired with Flux.1 Dev Fill, which achieved SOTA on VITON HD benchmark on November 24th, 2024 when compared against FitDiT, IDM-VTON, StableVITON, and others. In my use, it averaged 35 seconds to generate a single try on. The creator suggests setting 30 steps and 30 guidance scale under advanced settings for best results here.
Note: I used the suggested defaults by the creators of every live demo.
Mystery Model (???)
To make the comparison more interesting, I also included the current (closed-source) state of the art try-on model, to also show how the top open-source models compare to other market-leading solutions. It runs in ~7 seconds and outputs in 1MP resolutions.
Quick facts: 7 seconds per try on, native 1MP output resolution
Understanding Top VITON Model Differences
Q: How does StableVITON's approach compare to standard fine-tuning?
A: StableVITON follows the ControlNet philosophy: keep the original Stable Diffusion 1.5 model completely frozen, and train only a lightweight side network that guides generation. Specifically, it duplicates the SD encoder, trains that copy, and uses its outputs to influence the decoder through cross-attention layers - just like ControlNet does with edge maps or poses.
Instead of guiding the model with text prompts, StableVITON uses visual inputs like the garment image, mask, and DensePose map. The frozen SD model still does all the generation; StableVITON just acts like a smart adapter that translates clothing cues into something the model can follow.
Q: How does OOTDiffusion differ from traditional warping approaches?
A: Traditional methods handle try-on in separate stages: first warping the garment to match the person’s pose, then pasting it in place, and finally blending it. Each step introduces room for error, often resulting in unnatural or misaligned results. OOTDiffusion skips this disjointed pipeline entirely. Instead, it leverages diffusion models that learn to paint the garment gradually (denoising steps) but directly onto the person image, handling warping, alignment, and blending in one cohesive process.
Q: What makes IDM-VTON's frozen approach unique compared to typical training methods?
A: Most previous try-on models, like StableVITON, follow a common pattern: take a large, powerful pre-trained model like SDXL, freeze it, and then add small external modules to gently steer its output (e.g., via extra encoders or cross-attention). The assumption is: “this backbone is so good, we shouldn’t touch it.”
IDM-VTON flips this idea on its head. Instead of freezing the core and steering it, IDM-VTON freezes the SDXL-based garment encoder and uses it only as a feature extractor. The main SDXL model is fully trainable, making it one of the first approaches to directly teach the backbone how to perform virtual try-on itself. It’s a role reversal: the frozen part just observes garments, while the core model learns the full task end-to-end.
Q: Why is CatVTON's spatial concatenation different from cross-attention methods?
A: Most try-on models rely on cross-attention layers or parallel networks to merge garment information with the person image, making the architecture bulky and complex.
CatVTON takes a radically simpler approach: it just stitches the garment and person images side-by-side (plus a mask channel), and feeds the whole thing into a single compact network. No extra attention blocks. No separate garment encoder. No pose estimation. Just one streamlined network that learns to process both inputs as one coherent image.
What’s most impressive is that this minimal design still delivers results comparable (and in some cases superior) to heavier dual-net models. And it does so at high resolution (1024×768) in ~35 seconds on a regular GPU with under 8 GB VRAM. It’s a rare case where less complexity actually performs better.
Q: What's the main advantage of parallel UNets versus single-model approaches?
A: Parallel UNet models like OOTDiffusion and IDM-VTON use two separate networks: one studies the garment, and the other focuses on putting it onto the person. This split can help with preserving details but usually requires more memory and longer processing times.
Single-model designs like CatVTON handle everything in one lightweight network. They’re faster, simpler, and easier to run on everyday hardware, though they may be less specialized in theory.
Q: Which approach is actually better for everyday users?
A: If you want fast results on a regular GPU, CatVTON is your best bet: it’s quick, light, and works well even on gaming laptops. If you have more powerful hardware and care about getting every clothing detail just right, models like IDM-VTON could offer slightly better quality.
That said, our testing shows that CatVTON’s simple design often matches or even beats more complex models, making it surprisingly strong for everyday use.
How Will We Test These Models?
Virtual Try On models take a model and clothing images as inputs, then output digital try on results of the model wearing the clothing. We’re going to benchmark these models against each other in a battle against each other.
We’ll use these models for this showdown.

A photo of the two models that we will be using for our comparison.
Methodology
To be fair, we’re going to run each garment through each virtual try on model 4 times and choose the best result of the 4 generations. Diffusion models have some randomness in the outputs that they generate due to their seed - as a result, we can adjust this parameter to get better results. With every new generation, we get a new color, garment placement, and texture.
Editor's Note: IDM-VTON expects input images to be in a 3:4 aspect ratio, so if your model image doesn’t match that format, make sure to check the “crop” option in the demo to prevent the output from appearing vertically compressed.
Round 1: Puffer Jacket Showdown
Let’s see how each VITON model does with a branded Puffer Jacket.

OOTDiffusion performs the weakest in this case. CatVTON is more accurate - it correctly reproduces all 5 padding sections, while IDM-VTON only generates 4. That said, IDM-VTON stands out with more detailed and realistic textures.

Round 2: Plain Black T-shirt with Minimal Design
Let’s try a simpler garment to see if it fares any better, a plain black T-shirt with a minimal graphic design.

A plain black graphic t-shirt flat lay with the text "FASHN AI"
It’s interesting that OOTDiffusion still struggles with this simpler try-on, despite rendering the text correctly. CatVTON does a better job with the text, but IDM-VTON once again stands out with more accurate colors and a more natural fabric appearance.

Round 3: Baggy Jeans with Complex Design
Time to try to swap clothing on a different part of the body - the pants.

The available OOTDiffusion demos didn’t support lower-body garment swaps, so I had to exclude it from this comparison. In my opinion, CatVTON delivers the best results among the open-source models.

Round 4: Complex Print Dress
Now for dresses - check it out.

CatVTON was more accurate in capturing the overall structure and shapes, while IDM-VTON did a much better job with textures and color fidelity.
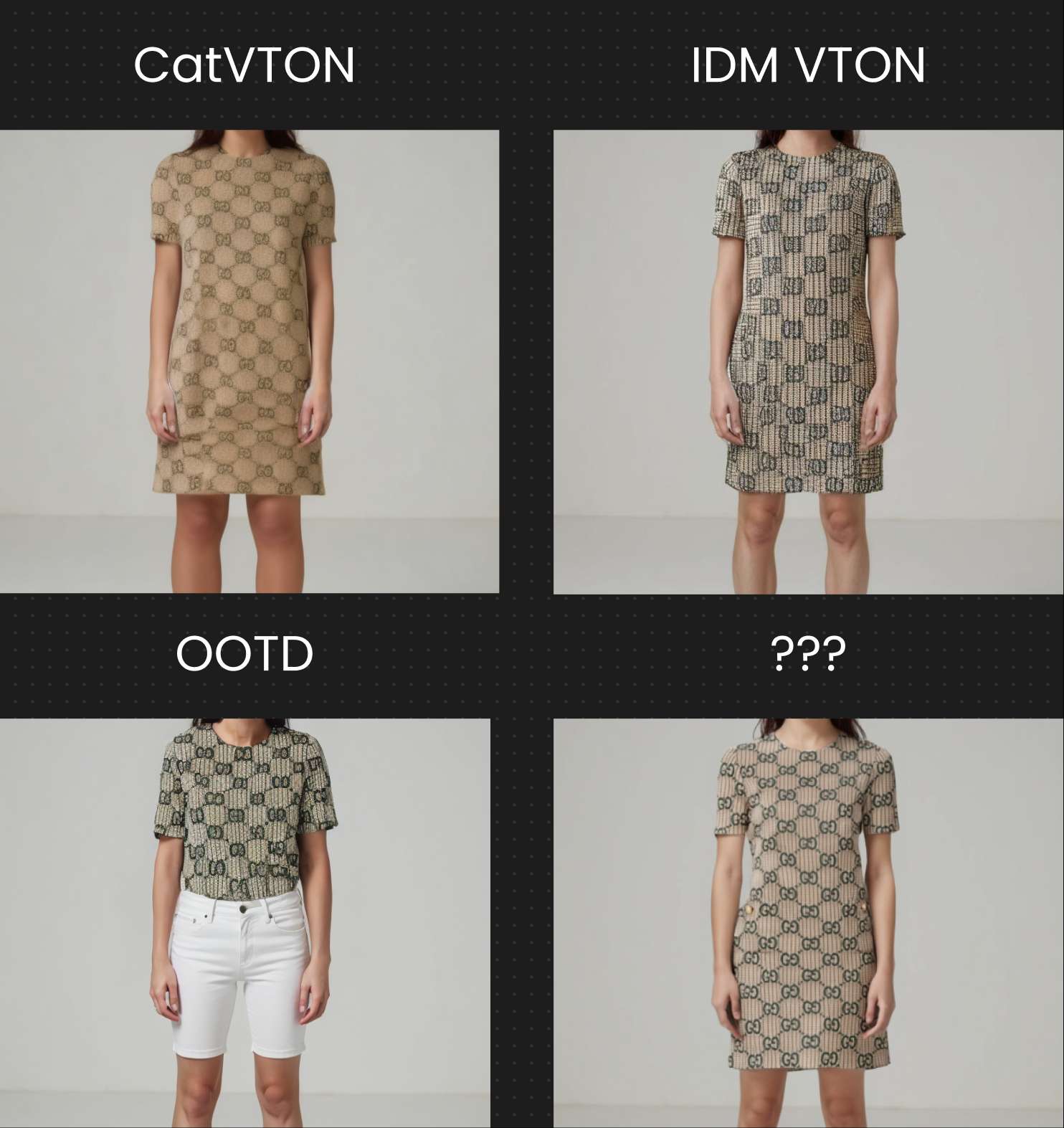
This is a clear example of the difference between a single-model approach and a two-UNet architecture. Injecting fine-grained texture information plays a crucial role in preserving subtle visual details.
Technical Information
Here are some additional, more granular statistics that may be useful to know before we wrap this comparison up:
| Model | Average Time to Generation | Demo Link Hardware | Demo Link |
|---|---|---|---|
| CatVTON | 11~ seconds | A100 | Link |
| IDM VTON | 17~ seconds | A100 | Link |
| OOTD | 46~ seconds | L40S | Link |
| ??? | 7~ seconds | ??? | Link |
Reveal & Final Thoughts
Overall Impression
Based on first impressions from this test, CatVTON stands out as the strongest open-source virtual try-on model available today. When paired with Flux 1.Dev, it consistently produced faster results and showed better alignment with the overall shape and structure of garments.
Meanwhile, IDM-VTON impressed with its detailed fabric textures and color accuracy, making it a solid alternative if your priority is visual richness over speed.
Production Readiness
Both CatVTON and IDM-VTON have real potential for practical use, especially if you’re willing to build custom workflows around them. They aren’t plug-and-play solutions, but with some effort, they could support creator tools, prototyping, or internal styling tools.
Note: both CatVTON and IDM-VTON are released under the CC BY-NC-SA 4.0 license, which prohibits any commercial use without obtaining a separate license.
OOTDiffusion, while not production-ready in its current state, deserves credit as a stepping stone. It introduced architectural ideas that clearly influenced IDM-VTON and helped advance the field overall.
Mystery Model
If open-source isn’t a must-have and you’re simply looking for the highest-quality results with zero setup, the FASHN Virtual Try-On Model is the fastest and most accurate commercially-permissible system that we tested.
Whether you prefer a simple UI, need API access, or just want production-ready results without the technical hassle, FASHN AI makes it easy to get started. Free to try and ready in seconds.